Paper: Can LLMs Generate Higher Quality Code Than Human? An Empirical Study. 2025
1 What do they do, and what’s the result?
1.1 What do they do?
1.1.1 This paper conducts an empirical analysis of AI-generated code to assess whether LLMs can produce correct and higher-quality code than humans. It evaluates the code quality of 984 code samples generated by GPT-3.5-Turbo and GPT-4 using simple, instructional and enhanced prompts, against input queries from the HumanEval dataset.
1.1.2 Firstly Calculate code quality metrics:
We enhance the HumanEval benchmark by calculating code quality metrics for the human-written code it contains. Code quality metrics are calculated using established tools like Radon, Bandit, Pylint, and Cimplexipy, with human-written code serving as a baseline for comparison.
Say, this paper compared AI-gen code with human-written code, where human-written code serving as the baseline. They use GPT-generated code as AI-gen code, and HumanEval dataset as human-written code.
HumanEval has some evaluation factors and test cases, and this paper, not only (1) utilized these factors and test cases for its experiments, but also (2) calculate the code quality metrics for HumanEval’s code snippets.
1.1.3 Then Rank their performance:
To quantify performance, we employ the TOPSIS method to rank the models and human code by their proximity to ideal and anti-ideal code quality metrics.
1.2 What’s the result?
1.2.1 For human-centric factors, AI performs better in Cyclomatic Complexity (CC), Cognitive Complexity (CogC), Lines of Code (LoC) and Vocabulary Size.
1.2.2 GPT-4 with advanced prompts, produces code closest to the ideal solution, outperforming human-written code in several metrics.
1.3 Others
1.3.1 The challenge is to ensure that the generated code is not only functionally correct but also safe, reliable and trustworthy.
2: Can I use any of it in my work? If yes, how?
2.1 Experiments Methodologies
2.1.1 use simple, instructional, and advanced prompts to generated code. Then let the AI-generated code against with human-written code.
2.1.2 Tools for calculating code quality metrics: Radon [14], Bandit [15], Pylint [16], Complexipy [17].
2.1.3 Tool for quantifying performance, say, ranking the AI-gen and human-gen codebases:
TOPSIS, Technique for Order of Preference by Similarity to Ideal Solution [18].
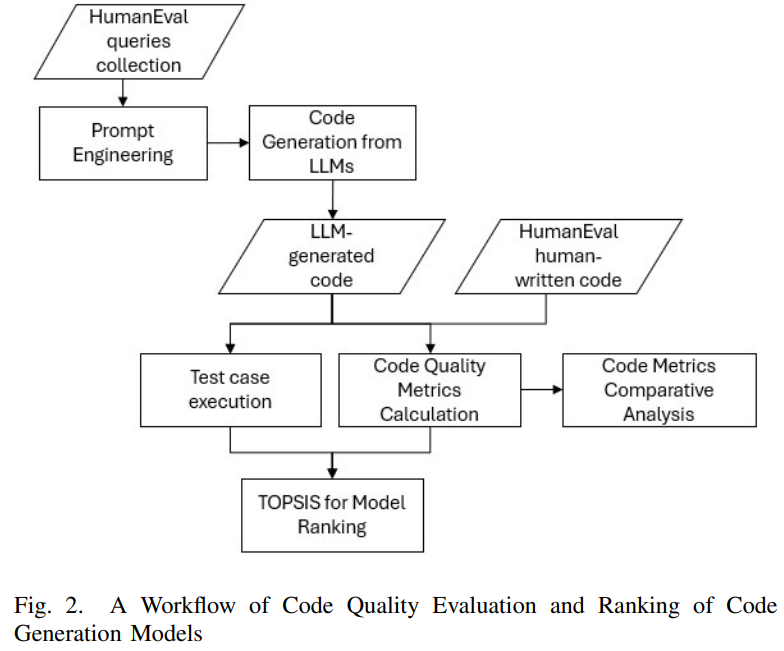
2.1.4 The experiment workflow
(1) Generate prompts in 3 types: basic, instructional, enhanced/advanced.
(2) Generate the code quality metrics for both the model-gen code and human-written code.
(3) Compute the code quality metrics for each code sample of both model-gen code and human-written code.
(4) Conduct a comparative analysis of some code quality metrics, e.g., correctness, readability, maintainability, security, adherence to best coding pratices.
(5) Perform TOPSIS analysis to rank the model-gen and human-gen code, based on both critical quality aspects (e.g., correctness and security) and human-centered quality factors (e.g., readability, maintainability, and complexity).
2.1.5 Various prompts design
(1) Simple Prompt
Simply request for a code solution.
(2) Instructional Prompt
-> Instruct the model to ensure the generated code passes the test cases
-> Instruct the model to limit output
-> Instruct the model to retain the original function definition, to not produce undefined function or nested functions
-> Instruct the model to ensure the code is free from syntax and semantic error
(3) Enhanced Prompt
-> Provide additional context
-> Explicitly request for code optimization through enhanced readability, safety, and lower complexity
-> Error handling
-> Focus on performance and clarity
3: Sparked ideas, thought or questions?
3.1.1 Question: AI-gen code might have better performance and is safer than human-written code, as shown in this paper. But, how will it perform in industry-level projects that consist of directory structure consideration, projects architecture, unit tests, etc.?
3.1.2 Evaluate complexity of configuration-prompt-gen code and normal-prompt-gen code?
“cyclomatic complexity and maintainability index help identify areas of high logical complexity that may affect readability and maintainability. Radon outputs numerical scores that represent the complexity of individual functions or modules, with higher values often indicating greater complexity.”
4: Knowledge or useful tools, tricks.
4.1 Overall
4.1.1 Code Quality Metrics
(1) The metrics: correctness, readability, maintainability, security, adherence to best coding pratices.
Cyclomatic Complexity (CC) –> efficiency?readability?; Cognitive Complexity (CogC) –> readability, Maintainability Index (MI) –> maintainability, Lines of Code (LoC) –> ?.
(2) Calculating tools: Radon, Bandit, Pylint, Complexipy.
4.1.2 Tool for quantifying performance, say, ranking the AI-gen and human-gen codebases:
TOPSIS, Technique for Order of Preference by Similarity to Ideal Solution.
4.2 HumanEval Dataset
The HumanEval dataset is a collection of Python programming problems which are written by humans. Each problem includes a function signature, docstring, body, and several unit tests, with an average of 7.7 tests per problem. It consists of 164 original programming problems, assessing language comprehension, reasoning, algorithms, and simple mathematics. The intended usage of the HumanEval dataset is to evaluate the functional correctness and problem-solving capabilities of various code generation models against the HumanEval dataset.
4.3 Code Metrics Tools
To evaluate code quality across human-written and AI-gen codebases, we use four widely used static analysis tools: Radon [14], Bandit [15], Pylint [16], Complexipy [17]. These tools provide complementary metrics that collectively address diverse aspects of code quality, enabling a balanced analysis of code. Additionally, they are widely used, in both academic and practical contexts, and readily integrable into automated evaluation pipelines. Each of these tools provides specific insights into different aspects of code quality.
4.3.1 Radon
Radon is a Python tool that computes various metrics from the source code. Radon can compute Halstead metrics, Maintainability Index, and McCabe’s complexity, i.e., cyclomatic complexity, raw metrics (LoC, LLoC, SLoC, comment lines, etc.).
Metrics like cyclomatic complexity and maintainability index help identify areas of high logical complexity that may affect readability and maintainability. Radon outputs numerical scores that represent the complexity of individual functions or modules, with higher values often indicating greater complexity.
(1) Cyclomatic Complexity, CC
CC corresponds to the number of decisions a block of code contains plus 1. This number, which also called McCabe number, is equal to the number of linearly independent paths through the code.
(2) Maintainability Index, MI
MI is a software metric which measures how maintainable (say, how easy to support and change) the source code is. The maintainability index is calculated as a factored formula consisting of Source Lines of Code (SLoC), Cyclomatic Complexity and Halstead volume.
(3) Halstead’s metrics
Halstead’s metrics form a set of quantitative measures designed to assess the complexity of software based on operator and operand usage within the code. Using the base values of operators and operand, Halstead’s metrics calculate additional measures to estimate the cognitive and structural effort involved in understanding and maintaining code:
– Program Vocabulary (ŋ): Defined as the sum of distinct operators and distinct operands. This metric reflects the unique linguistic elements in the code, with a larger vocabulary suggesting a more complex codebase.
– Program Length (N): The total number of operators and operands, representing the size of the program in terms of tokens used. Program length can indicate code verbosity, where excessive length may imply redundancy or inefficiency.
– Volume (V): Volume measures the size of the program in “mental space” and indicates the amount of information the code contains. Higher volume implies increased difficulty in understanding the program, as it occupies more cognitive resources.
– Difficulty (D): This metric quantifies the difficulty of understanding the program. Difficulty highlights how challenging the program might be for developers, with higher difficulty suggesting a more intricate flow of logic.
– Effort (E): Effort provides an estimation of the mental workload needed to implement or maintain the code. Effort serves as an indicator of development time, with higher values suggesting increased complexity and, consequently, a greater likelihood of defects.
– Time required to program (T): This metric provides an estimate of the time required for a programmer to implement or comprehend the code.
– Number of delivered bugs (B): This metric estimates the potential number of defects in the code, based on its complexity.
4.3.2 Complexipy
Cognitive complexity (CogC) captures the mental effort required to understand code, emphasizing readability and simplicity. The output consists of cognitive complexity scores, where lower values are preferable as they indicate easier-to-understand code. The complexipy tool for Python code checks the cognitive complexity of a file or function and if it is greater than the default cognitive (15), then the return code will be 1, otherwise it will be 0.
4.3.3 Bandit
Bandit is a tool which performs static code analysis for potential security vulnerabilities in Python code. Bandit processes each file, builds an AST from it, and runs appropriate plugins against the AST nodes. Once Bandit has finished scanning all the files it generates a report. It scans for common security risks, such as insecure imports or improper use of cryptography.
Bandit’s output includes a list of issues flagged with severity levels, enabling targeted remediation of critical vulnerabilities.
4.3.4 Pylint
Pylint is a static code analysis tool that checks for errors, enforces a coding standard, looks for code smells, and can make suggestions about how the code could be refactored. Pylint locates and outputs messages for errors (Err.), potential refactorings (R), warnings (W), and code convention (C) violations in code.
4.4 TOPSIS
The Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) is a multi-criteria decision analysis method.
TOPSIS is based on the concept that the chosen alternative should have the shortest geometric distance from the positive ideal solution (PIS) or ideal worst and the longest geometric distance from the negative ideal solution (NIS) or ideal worst. It compares a set of alternatives, normalising scores for each criterion and calculating the geometric distance between each alternative and the ideal alternative, which is the best score in each criterion.
Our goal is to rank various GPT model alternatives with respect to code generation quality and to find the best based on a set of code metrics. The idea is to choose the solution closest to the ideal solution (best values) and farthest from the worst (worst values).
[14] Radon. 2023
[15] Bandit. 2023
[16] Pylint. 2024
[17] Complexipy. 2021
[18] Multiple attribute decision making: methods and applications. 2011
END